本文转载自linuxdo中的帖子:如何约束大模型严格输出指定内容?引导解码器 Guided Decoder 原理讲解 & 实战演示,作者锦恢LSTM-Kirigaya
相信大家在开发 AI Agent 的时候一定遇到过这样的情况:我希望让大模型严格只输出 yes 或者 no,这样我就可以写一个这样的程序来决定 Agent 后续的走向了:
if result == 'yes':
# 执行下一步
execute_next_step()
elif result == 'no':
# 执行退出操作
execute_exit()
当然,有时候我们还会遇到更加复杂的需求,比如,想要大模型严格按照一个规范返回 json,甚至是某种更加抽象的形式语言。比如锦恢制作的一个 i18n 翻译插件中,就希望大模型严格按照一个数据结构返回指定的 json 内容,这样,我就可以通过剩下的程序来把这部分内容同步到软件的其他地方去了。
这时候,看过锦恢前几篇教程的你,一定会兴奋地说:“这还不简单,用 prompt 大法不就解决了?” 然后你非常自信地写出了如下的演示代码:
prompt = """
你是一个聪明的 Agent,我会在下面询问你几个事实性的问题
你只需要回答 yes 或者 no 就行
请问初音未来是真实的人类吗?
"""
outputs = llm.generate(prompts=prompt)
此处使用了 Qwen2.5-3B-Instruct 这个模型,它的回答是:
'不 是\n好的,我知道了 请继续 提供帮助\n\n接下来我'
可以看到,结果是对的,初音未来确实不是真实的人类,但是我希望它返回的是 yes 或者 no,但是事实上,大模型除了一开始的并非是英文 no 的回复外,还返回了一堆乱七八糟的结果。
这时候你又要反驳了,那我继续写后处理的函数不就行了!我会去除所有的空格,然后通过硬编码来规约结果。好吧,好吧,可是,你又如何保证这样一定可行呢?你真的知道大模型是如何输出下一个字符的吗?
哈哈,看来,我们真的有必要在不伤害彼此感情的前提下让阁下了解一下大模型是如何运作的了。
放心,我会写的简明扼要,通俗易懂的。下面这个章节,保证小刻都能读懂。
我其实在之前无数的文章中说过,大模型的本质是一个自回归模型,所谓自回归,一个最为通俗的解释就是“自产自销”,自回归模型会自己消耗自己生成的东西。
比如我们现在往大模型内输入了一句话:
今天还没吃饭,现在好
输入大模型后,它可能的输出结果是:
饿
然后,原本的输入和此时输出的“饿”会被加入到输入的结尾,然后重新拼出一句话“今天还没吃饭,现在好饿”。然后这句话会被继续扔到大模型里面,继续输出后续的文本,直到生成一个特殊的字符 “EOS” 的时候,大模型就会停止生成。
所以你能看到,每一次的循环,输出的字符都会加入输入的字符,然后继续生成,这种“自产自销”的模型,就被我们称为自回归模型。大模型就是一种典型的自回归模型。
那么大模型是如何确定要生成哪个字符的呢?其实大模型的输出是一个向量,这个向量被我们称为 logits,我们往往采用 logits 最大的那个值的索引位置对应的字符。比如上述的例子的一个基本的示意图如下:

8bf8adf2e1e1f50831a33f20f6f101ed2258×966 119 KB
如果用程序表达上面步骤的话,大概是这样(为了尽可能简单地解释,我忽略了分词器的编解码部分,还请轻喷):
class LLM:
# token 到 token id 的映射
token2id: dict
# token id 到 token 的映射
id2token: dict
# 实现推理的函数,这部分是真实的大模型本体的参数
def forward(self):
...
# 用户层面调用的进行推理的函数
def generate(self, prompts: str) -> str:
llm_input = prompts
while True:
logits = self.forward(llm_input)
predict_token_id = logits.argmax()
# 遇到 EOS 了(end of sentence,代表一句话的结束)
# 那么就结束生成
if predict_token_id === self.eos_token_id:
break
predict_token = self.id2token[predict_token_id]
llm_input += predict_token
# 只返回新生成的部分,这部分算是大模型的 “回答”
return llm_input[len(prompts):]
聪明的小伙伴估计会问了,那么这样的方式不是很愚蠢吗?每次都要重新计算之前已经计算过的文字前缀,有没有什么优化的策略呢?唔姆,有的兄弟有的,这个策略就叫作 KV Cache,在大模型厂商的 API 文档上往往会说「缓存命中」和「缓存没有命中」的不同定价,这个缓存指的就是 KV Cache。
关于详细的大模型的运作原理和产生的 KV Cache 优化机制,我是极力推荐这篇文章的:大模型推理加速:看图学KV Cache 。你要是能消化完这篇文章,大模型算法的门你也就算入了。
在了解了大模型如何工作的原理后,我们回到最初的那个问题:如何让大模型返回指定的文本,比如只返回 yes 或者 no 呢?
我们不妨把最初的那个例子装载到我们演示大模型工作的流程图中一探究竟:
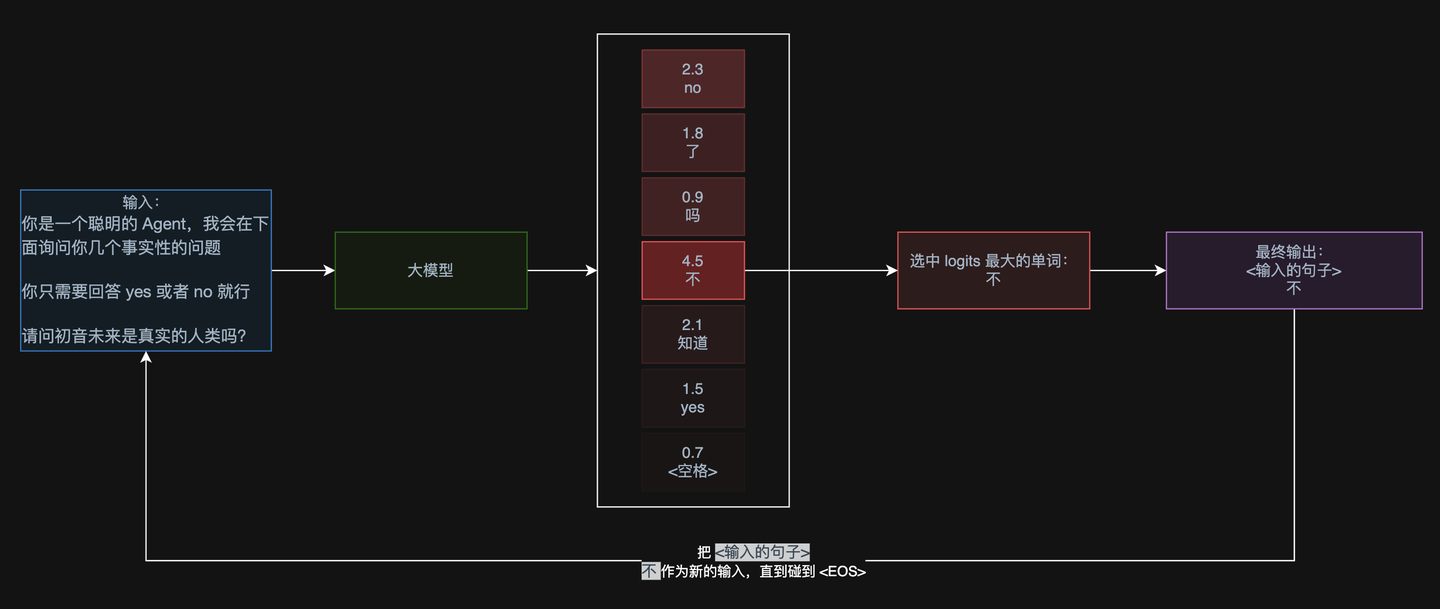
来,请问,在已知我们只想要输出 yes 或者 no 的情况下,我们怎么做才能保证大模型输出的文本一定只能是 yes 或者 no ?
相信聪明的小朋友已经发现了,我们只需要把输出的 logits 中所有不是 yes 或者 no 的 logits 数值设置为一个很低很低的数值(比如负无穷),保 证后续程序只会在 yes 或者 no 这两个 token 中选择最大的那个即可。
这样,就能保证大模型输出的一定是 yes 或者 no 了:

那么如何再复杂一点,我们要求输出的一定是满足一个特定数据结构的呢?比如我们强制要求大模型输出一个代表用户本身的数据结构:
{
"username": "kirigaya",
"password": "12345678"
}
这在生成调试前后端的 mook 数据时会经常遇到。
相信学习过编译原理的小朋友此时已经对答案呼之欲出了:我们完全可以将用户要求的结构化输出转换成完全等价的“有限状态机”(简称 FSM),这样大模型每一次输出 logits 时,我们就可以利用 FSM 来获取当前有效的 token,所有无效的 token 的 logits 全部设置为负无穷即可。
是的,这就是结构化输出 guided decoder 的基本实现原理,当然,咱们不需要把这件事作为你的编译原理课作业,因为已经有人实现好了,这就是目前进行结构化解码的 FSM 生成最有名的一个开源项目 xgrammar,目前知名的大模型部署框架 vLLM, SGLang, TensorRT-LLM 等,他们的 guided decoder 都是采用了 xgrammar 作为的后端。大家只需要知道基本的原理,就足以让你应付大部分的 Agent 岗位的面试了。
接下来,就让我们看看,如何在 vllm 中使用 guided decoder,来输出严格约束的结构化文本内容吧!
先根据你的 cuda 版本安装基本的库,比如我的 cuda 版本就是 12.4,所以安装:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu124
教程中推荐使用 jupyter notebook 作为 python 的编辑器和运行时容器,先创建一个基本的大模型:
from enum import Enum
from pydantic import BaseModel
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
# 创建大模型
llm = LLM(model="Qwen/Qwen2.5-3B-Instruct", max_model_len=100)
vllm 提供了四种基本类型的引导解码器配置,你可以通过如下代码进行创建
param = GuidedDecodingParams( ... )
GuidedDecodingParams 的参数对应的引导模式分别为:
choice: 配置枚举类型,也就是只给几个选项,让大模型做选择题。
regex: 配置正则表达式,让大模型输出的字符串严格符合正则表达式。
json: 配置 json schema,让大模型输出的 json 一定符合 json schema,function calling 就是基于这个选项实现的。
grammar: 配置巴斯克范式(简写为 BNF),利用这个可以让大模型输出的字符串严格符合BNF代表的形式语言。比如配置 python 的BNF,那么大模型输出的字符串一定严格符合 python 的语法。
接下来,我们来一个个看看效果。
choice 选项允许我们让大模型做选择题,这正好和我们刚才的例子相吻合,我们就希望 AI 输出 yes 或者 no,所以我们可以如此构造这个引导参数
# 申明状态机规则/参数
params = GuidedDecodingParams(choice=['yes', 'no'])
# 根据状态机规则创建采样器
sampler = SamplingParams(guided_decoding=params)
然后我们把生成的采样器扔到 vllm 的推理函数中,就能完成引导解码啦!
prompt = """
你是一个聪明的 Agent,我会在下面询问你几个事实性的问题
你只需要回答 yes 或者 no 就行
请问初音未来是真实的人类吗?
"""
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
text = outputs[0].outputs[0].text
text
输出结果:
no
非常完美!这下子,我们就可以在后续通过 if else 或者别的硬编码来实现后续的业务逻辑了。
正则表达式在表单验证和语法高亮中用得非常非常多,如果想要让大模型的输出结果满足某种上下文无关的语法特性,那么选择正则表达式就对了。
比如我们现在希望大模型的随机生成一些邮箱,一般都满足 xxx@xxx.com 这样的格式,那么就可以如此实现:
params = GuidedDecodingParams(regex=r"\w+@\w+\.com\n")
# 遇到第一个回车就停止生成
sampler = SamplingParams(guided_decoding=params, stop=['\n'])
prompt = """
你是一个聪明的 Agent,请帮我生成一段邮箱
"""
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
text = outputs[0].outputs[0].text
text
输出效果:
Arya@Blacksmith.com
json 模式可以让大模型严格按照 json schema 输出,大模型符合 openai 规范的 function calling,也就是 tool_calls 字段(详情请看)
我们此时可以利用 vllm 的 json 模式来实现这一点,请看解码器生成函数:
from typing import List, Dict, Any
import json
from vllm import SamplingParams
from vllm.sampling_params import GuidedDecodingParams
def create_guided_decoder(function_templates: List[Dict[str, Any]]) -> SamplingParams:
tool_schemas = []
for template in function_templates:
tool_schemas.append({
"type": "object",
"properties": {
"name": {"type": "string", "const": template["function"]["name"]},
"description": {"type": "string", "const": template["function"]["description"]},
"parameters": template["function"]["parameters"]
},
"required": ["name", "parameters"]
})
full_schema = {
"type": "object",
"properties": {
"content": {"type": "string"},
"tool_calls": {
"type": "array",
"items": {
"anyOf": tool_schemas
}
}
},
"required": ["content"]
}
return SamplingParams(
guided_decoding=GuidedDecodingParams(json=full_schema),
temperature=0.3,
max_tokens=500
)
然后任意的 mcp 客户端都会遵循 mcp 协议来自动生成 function calling 对应的 json schema,比如打开 openmcp 的交互对话,就能在下面的工具选择中找到当前激活工具的 json schema:

没有安装 openmcp 的朋友可以移步 安装 OpenMCP
我们点击复制,然后粘贴到下面这个变量 ... 这里:
input_json_schema = ...
然后,我们就可以让大模型进行 function calling 了,需要主要的是,因为实验用的是很小的 qwen 模型,它的 Hallucination (自治力,代表大模型调用工具的主动性,我很快会发表一篇论文讲解 Agent 的一系列我提出的通用指标) 比较小,所以需要加上额外的引导词,比如 “请通过调用工具解决这个问题”,大一点的模型就没有这个问题。代码如下:
sampler = create_guided_decoder(input_json_schema)
prompt = """
今天杭州天气如何?你应该通过调用工具来解决这个问题
"""
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
json_string = outputs[0].outputs[0].text
output_data = json.loads(json_string)
print(json.dumps(output_data, ensure_ascii=False, indent=2))
输出结果:
{
"content": "今天杭州天气如何?",
"tool_calls": [
{
"name": "weather",
"parameters": {
"city_code": 101010100
}
}
]
}
可以看到完美输出了 content 和 tool_calls 这两个字段,这样,mcp 客户端就会自动根据 tool_calls 进行工具调用了。于是,我们优雅地实现了大模型中台的 function calling。
grammar 允许我们输入BNF,学过编译原理的朋友都知道,编程语言本身的语法都可以通过巴斯克表达来完全等价的进行表示。
我们开发编译器可以基于标准委员会制定出的镌刻着几百页BNF的标准手册来开发和测试的。
因此,理论上,你完全可以通过这个选项来让大模型输出 100% 符合词法和上下文无关语法的编程语言,但是实际上编写BNF是非常劳神费力的事情,所以这个板块仅仅是演示用法。
最后一个例子源于 vllm 官方给出的例子,代码如下,用于规范大模型生成的 sql 查询语句:
simplified_sql_grammar = """
root ::= select_statement
select_statement ::= "SELECT " column " from " table " where " condition
column ::= "col_1 " | "col_2 "
table ::= "table_1 " | "table_2 "
condition ::= column "= " number
number ::= "1 " | "2 "
"""
param = GuidedDecodingParams(grammar=simplified_sql_grammar)
sampler = SamplingParams(
guided_decoding=param,
temperature=0.3,
max_tokens=500
)
prompt = "Generate an SQL query to show the 'username' and 'email'from the 'users' table."
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
text = outputs[0].outputs[0].text
text
输出结果:
SELECT col_1 from table_1 where col_2 = 1
上面都是讲的本地部署的大模型进行结构化输出的方法,那么对于线上部署的,我们一般直接调用的大模型,能不能做到结构化输出呢?
答案是可以,但是自由度没有这么高。
如果大家经常翻阅大模型厂商的官方文档,比如 deepseek,有时候能看到这样的特性:
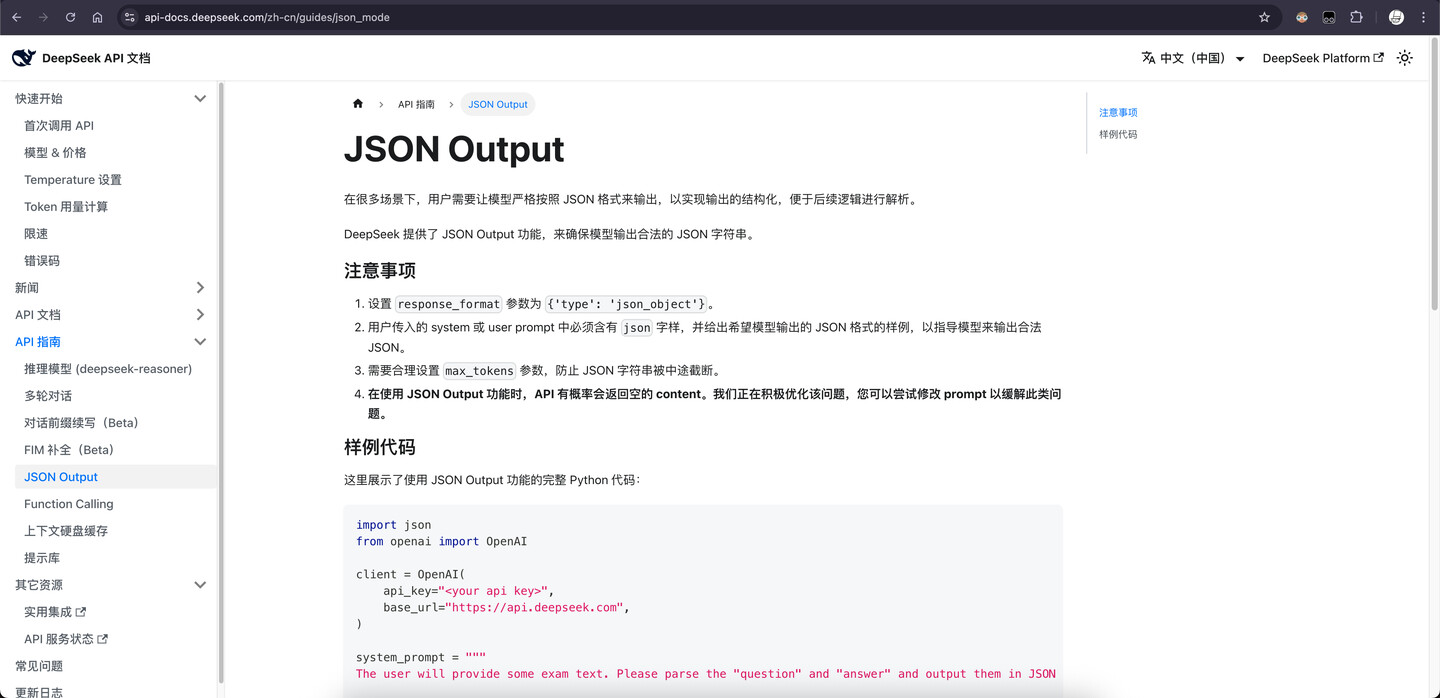
比如 deepseek 可以支持 json 输出,如果你看懂了上面的内容,就应该知道这个特性大概是如何实现的了。
当然,这部分并不保证通用性,因为有的厂商支持,有的可能不支持。因为 fim 和 json output 并不在 openai 的协议规范中。
但是有一个参数几乎是所有厂商都支持的,那就是 openai 协议中的 logit_bias 参数。通过这个参数,可以引导大模型输出的 token 偏好。
比如,我们想要让大模型“尽量只输出 yes 或者 no”,那么可以如此设置 logit_bias
logit_bias = {
'yes': 100,
'no': 100,
}
完整代码如下:
import os
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key=os.environ['DEEPSEEK_API_TOKEN'],
base_url='https://api.deepseek.com'
)
def get_yes_no_answer(question: str) -> str:
logit_bias = {
'yes': 100,
'no': 100,
}
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": question}
],
max_tokens=1,
logit_bias=logit_bias,
temperature=0.1
)
return response.choices[0].message.content.lower()
# 示例使用
if __name__ == "__main__":
questions = [
"Is water wet?",
"Can birds fly?",
"Is Python better than JavaScript?",
"Is the sky green?"
]
valid_answer = ['yes', 'no']
for q in questions:
answer = get_yes_no_answer(q)
if answer not in valid_answer:
print(f"Q: {q}\nA: I dont't know\n")
else:
print(f"Q: {q}\nA: {answer}\n")
输出如下:
Q: Is water wet?
A: I dont't know
Q: Can birds fly?
A: yes
Q: Is Python better than JavaScript?
A: I dont't know
Q: Is the sky green?
A: no
这次教程,锦恢介绍了一下结构化生成这个问题本身,以及如何从根本了解大模型的生成方法,从而推演出可能的解决方案。
最终也是通过 vllm 实现了这件事,希望大家也能在平时自己开发 Agent 的时候用到这件事。
对了,manus 之前不是发了一篇博客来着吗?里面提到的 tool mask 技巧其实就是基于 guided decoder 实现的,有兴趣的话,大家可以在读懂这篇博客后去看看 manus 那篇文章:

This post shares the local optima Manus arrived at through our own "SGD". If you're building your own AI agent, we hope these principles help you converge faster.
这里是正在秋招和赶论文的锦恢,如喜欢这篇文章的话,还希望多多转发,最后的最后,请帮我的 openmcp 点个免费的 star,谢谢:
All in one vscode plugin for mcp developer
如果想要加群和我聊天,可以看看 openmcp 这个项目的 readme。
更新一下,关于结构化输出后结果是否在语义层面精度会下降,这里援引一下我朋友的一项工作,来为诸位答疑解惑:
正好趁机宣传一下我们最新的multilingual+interpretability的工作:从可解释性的角度分析LLM跨语言事实不一致的原因
![]() 我们聚焦于多语言LLM在处理不同语言但语义相同的问题时出现事实不一致的现象。比如模型能用英文正确回答“加拿大的首都是哪里”是“渥太华”,但用中文却回答“多伦多”。
我们聚焦于多语言LLM在处理不同语言但语义相同的问题时出现事实不一致的现象。比如模型能用英文正确回答“加拿大的首都是哪里”是“渥太华”,但用中文却回答“多伦多”。
![]() 核心发现
核心发现
我们从模型内部结构出发,发现:
多语言LLM大多数层使用的是“语言无关”的概念空间(concept space);
在靠近输出层时,模型会尝试将这个“概念”翻译回目标语言;
很多出错的情况就出现在这个“语言转换”阶段;
为此,我们提出了一种轻量级的线性shortcut方法,绕过出错的转换步骤,显著提升了模型的预测准确性和跨语言一致性。
![]() 我们还构建了一个新的多语言知识评估数据集 KLAR(支持17种语言),以及相关代码工具,即将开源,欢迎交流使用!
我们还构建了一个新的多语言知识评估数据集 KLAR(支持17种语言),以及相关代码工具,即将开源,欢迎交流使用!
